2025.07.10: VIVID-10M dataset is released on Huggingface.
VIVID is a versatile and interactive video local editing model trained on VIVID-10M dataset, which supports entity addition, modifiation, and deletion.
Given a video, VIVID generates high quality, harmonious contents within the mask sequence, guided by the semantics of local caption.
Inputs
Edited Video
A sleek, circular UFO hovers in the air, its metallic surface gleaming with a futuristic sheen. The round body is smooth and streamlined, with a slightly domed top and a series of glowing lights around its outer edge.
A woman is wearing a stylish crossbody bag that rests comfortably against her side. The bag features a chic design, made from soft leather, and is adorned with metallic accents and decorative stitching.
A pillow rests quietly on the sofa, made of warm velvet fabric in a gentle light blue color. Its surface is adorned with delicate white floral patterns, and the edges feature meticulous stitching. The pillow has a classic square shape and a moderate size, with a few subtle wrinkles that add character.
A rock star signs an autograph for a fan. Dressed in edgy rock attire, with tattoos and jewelry adding to their iconic look.Enthusiastic fans were blocked behind the fence and stretched out their markers and notebooks, asking for the star's autograph.The star holds a marker and carefully signs on the notebooks.Some security personnel stood between the celebrities and the bus, carefully observing the surroundings.
A small pond is situated at the center of the indoor space, its water crystal clear, with gentle ripples occasionally disturbed by a few golden koi swimming leisurely, adding vitality to the scene. The edges of the pond are adorned with natural stone, covered in moss and small plants, as if weathered by time. Floating on the water's surface are several white water lilies, their petals shimmering in the sunlight and emitting a subtle fragrance.
The black sunglasses showcase a trendy oversized design, crafted from lightweight and durable plastic. Their chic cat-eye shape flatters various face types, while the deep, reflective black lenses provide UV protection and a touch of allure. The arms are slightly tapered and feature subtle geometric patterns, enhancing their modern appeal.
The yellow sports car features a streamlined design, with a low profile and sharp lines that convey a sporty feel. The front is equipped with bold headlights and a distinctive grille, while the rear includes a stylish spoiler that enhances its performance appearance.
Remove objects and generate areas that blend with the background.
Remove objects and generate areas that blend with the background.
Remove objects and generate areas that blend with the background.
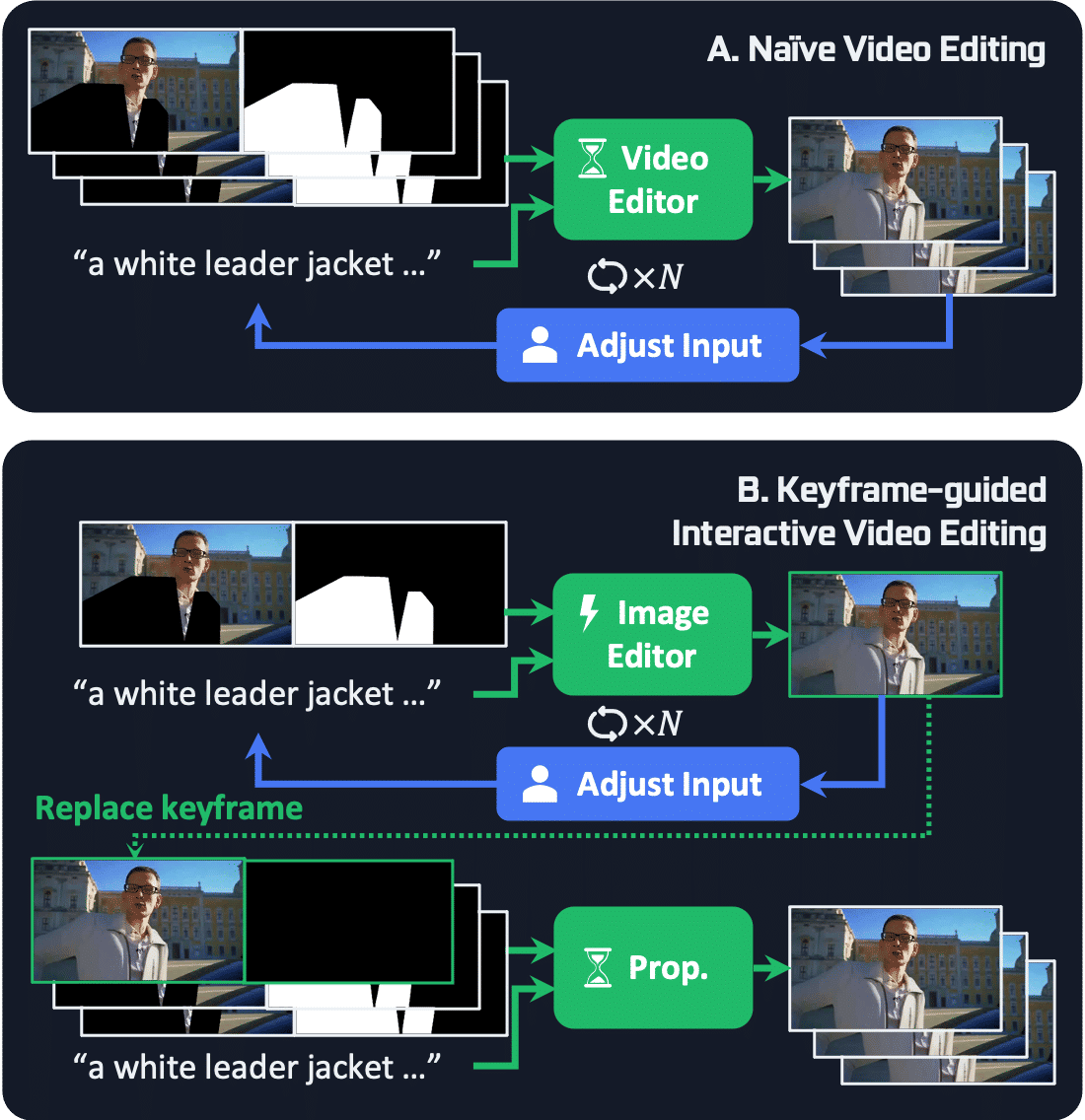
KIVE enables users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes.
Furthermore, the KIVE mechanism supports local editing of long videos by using the last frame of one edited clip as the keyframe for the next.

For example, if we want to edit a video as a Halloween promotional video ...
1. Draw Masks
2. Video Editing
17.1 PFLOPs
A skeleton is staring ahead.
3. Video Editing
17.1 PFLOPs
A skeleton is staring ahead, with flames flickering in his eyes.
1. Draw Masks
2. Keyframe Editing

1.5 PFLOPs
A skeleton is staring ahead.
3. Keyframe Editing

1.5 PFLOPs
A skeleton is staring ahead, with flames flickering in his eyes.
4. Edits Propagation
17.1 PFLOPs
A skeleton is staring ahead, with flames flickering in his eyes.
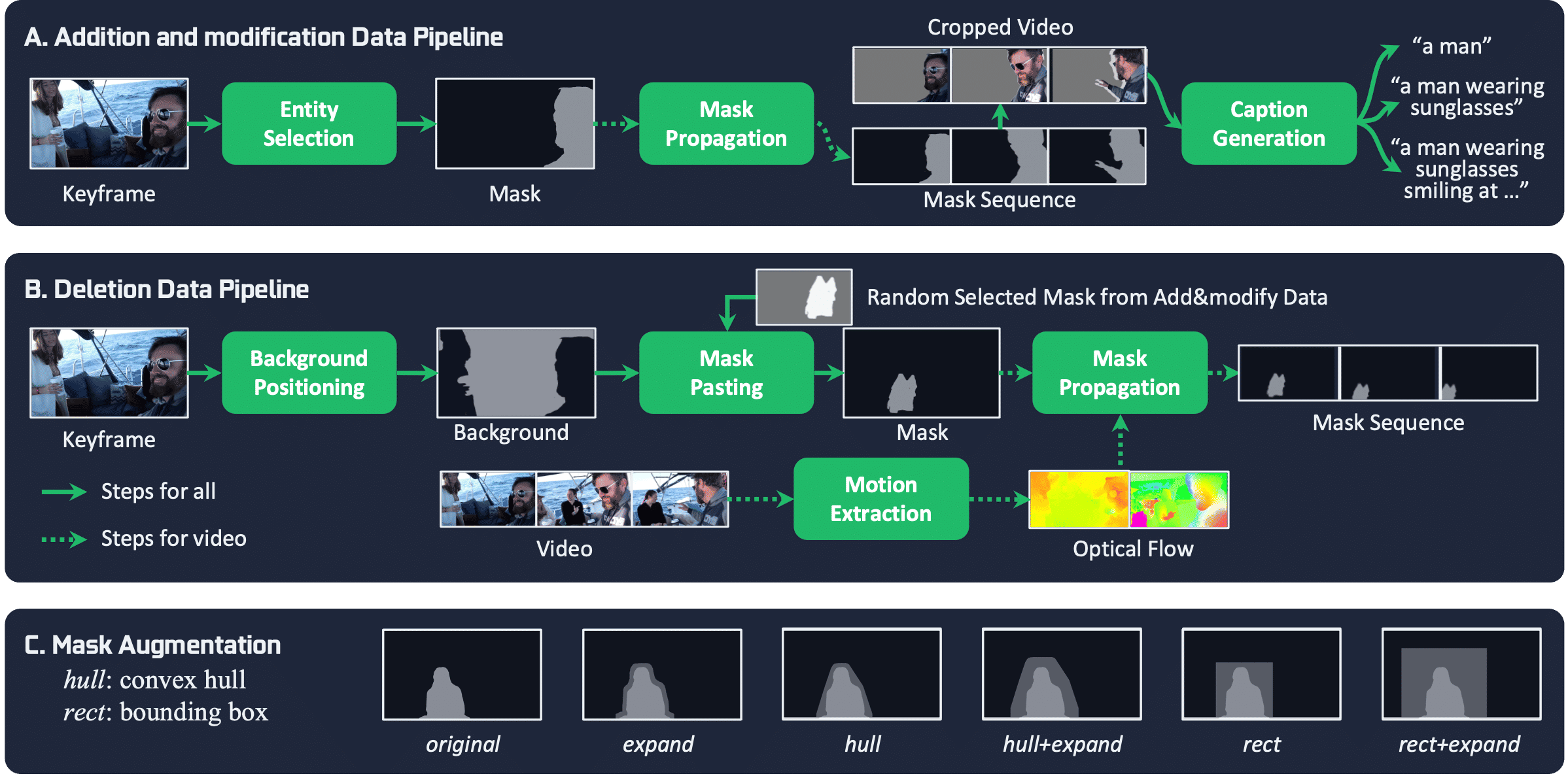
VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs.
VIIVD-10M comprises 9.7M samples that encompass a wide range of video editing tasks.
Ground Truth
Mask Sequence
Masked Video
Local Caption
A woman dressed in a black blazer adorned with golden buttons, complemented by a patterned scarf around her neck. She has short blonde hair and is wearing glasses. The background is textured with ornate designs. She holds a small object in her right hand and appears to be speaking or presenting. Her attire and overall demeanor suggest a formal or professional setting.
Ground Truth
Mask Sequence
Masked Video
Local Caption
A sculpture statue of a dynamic, white marble figure, likely representing a classical or mythological character, with its right arm raised and head turned upward as if capturing a divine moment. The intricate detailing includes flowing drapery that adds a sense of movement, emphasizing the figure's dramatic pose. The statue is mounted on a pedestal, which is placed prominently in a room with various paintings and a red wall, creating a harmonious blend of art forms.
Ground Truth
Mask Sequence
Masked Video
Local Caption
A cat with a predominantly black and white coat, possibly a tabby, running energetically in what seems to be a play area designed for pets. The area has green artificial turf flooring and includes various toys and small pieces of furniture, which are positioned randomly around the space. The cat's coat exhibits a classic tabby pattern with stripes and patches of solid fur, and it appears to be engaged in a lively activity within this environment.
Diffusion-based image editing models have made remarkable progress in recent years. However, achieving high-quality video editing remains a significant challenge. One major hurdle is the absence of open-source, large-scale video editing datasets based on real-world data, as constructing such datasets is both time-consuming and costly. Moreover, video data requires a significantly larger number of tokens for representation, which substantially increases the training costs for video editing models. Lastly, current video editing models offer limited interactivity, often making it difficult for users to express their editing requirements effectively in a single attempt. To address these challenges, this paper introduces a dataset VIVID-10M and a baseline model VIVID. VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs, which comprises 9.7M samples that encompass a wide range of video editing tasks. VIVID is a Versatile and Interactive VIdeo local eDiting model trained on VIVID-10M, which supports entity addition, modification, and deletion. At its core, a keyframe-guided interactive video editing mechanism is proposed, enabling users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes. Extensive experimental evaluations show that our approach achieves state-of-the-art performance in video local editing, surpassing baseline methods in both automated metrics and user studies. The VIVID-10M dataset and the VIVID editing model will be open-sourced.